The state of AI UGC tools, mid-2026
A field map of the AI user-generated-content tooling market in mid-2026 — what's actually a tool, what's still slideware, and where the category is heading.
The AI UGC category went from a handful of demos in early 2025 to roughly forty funded products by mid-2026. Most of them are a thin wrapper around the same three video models, repackaged with a different UI and a different starter tier. A few are not.
This piece is the field map. The full ranked verdict on each tool sits in the 2026 UGC ranking; this page is the topology — what kind of tool each one is, what category it actually sits in, and which ones are doing something the rest aren’t.
What counts as an AI UGC tool
We use a working definition that scopes the category tightly: a platform that takes a script or a product link, returns a publish-ready video of a synthetic creator delivering it, in under five minutes, for under five dollars per output, with usable lip-sync. By that bar, the field shrinks fast — most of the “AI UGC” tools you’ll see in pitch decks fail one of the three speed-cost-quality conditions.
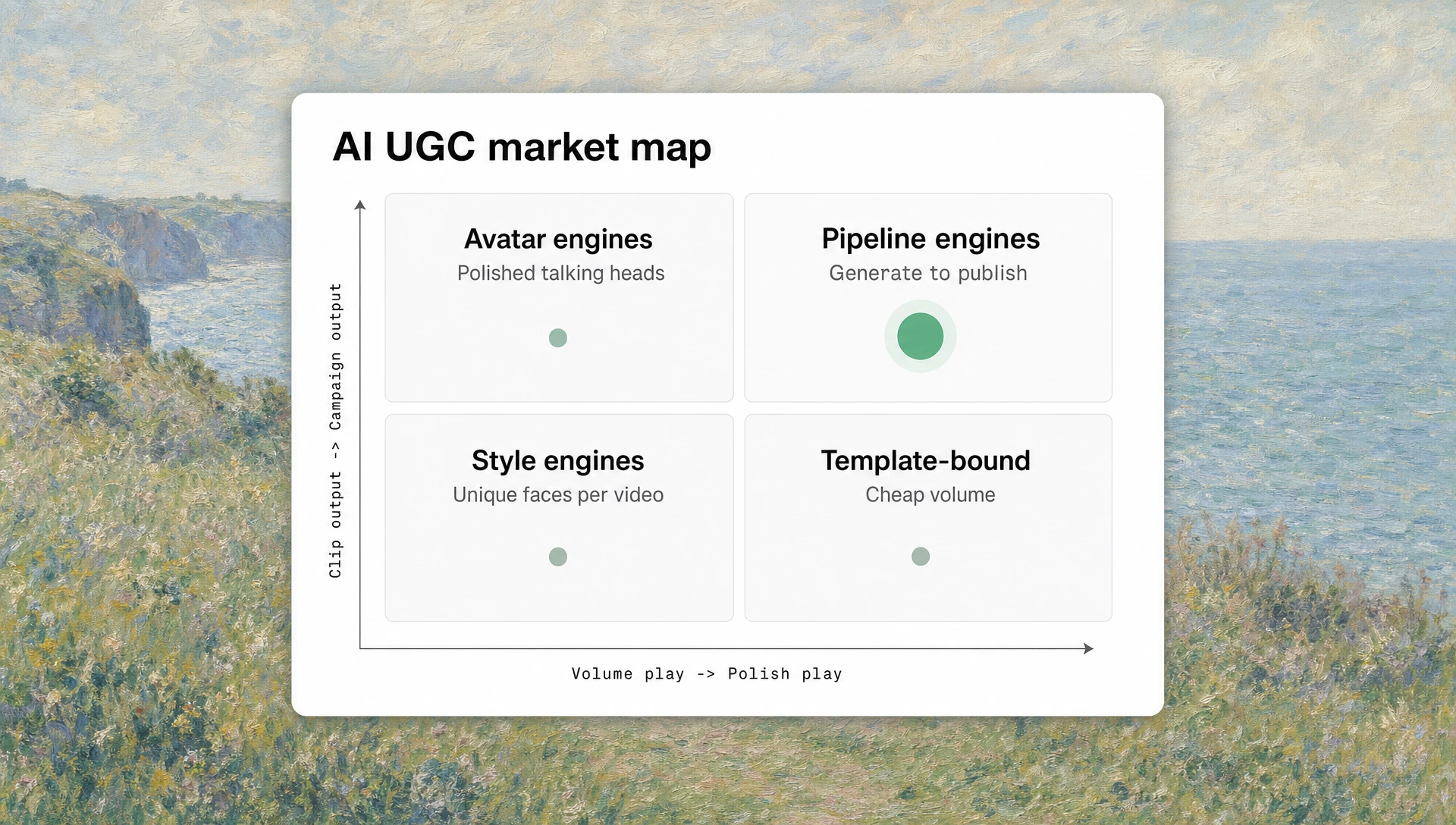
The forty-or-so vendors that show up in a Google search split roughly into four clusters by what they actually do.
The four clusters
Avatar engines. Sell a roster of licensed creator likenesses. HeyGen is the prototypical example, with about 700 avatars and the deepest non-English coverage in the field. Strong on speed and consistency, weak on differentiation — your competitor probably uses the same five faces. Best for: talking-head explainer, training, e-learning, long-form spokesperson content.
Style engines. Generate net-new faces per video. Strong on uniqueness — no two outputs look quite the same — but weak on serial campaign use. The “creator” you launch with on Monday won’t be recognizable on Friday. Best for: hook testing at volume, single-shot creative tests, content where the face is intentionally varied.
Pipeline engines. Chain a script LLM, a face generator, a voice clone, and a video model into one workflow. The output is a finished ad rather than a clip — captions, music, B-roll, multi-format export, sometimes the publish step too. Superscale is the most-developed example at mid-2026. Strong when they work, fragile when one link in the chain misfires. Best for: performance marketers who’d otherwise stitch four tools together.
Template-bound generators. Pre-made formats you fill with your script and your asset. Cheap, fast, and the easiest to onboard. The trade-off shows up after a few weeks of variants: outputs start to look like outputs. Best for: beginners on a starter budget, single-region English campaigns.
The cluster a tool sits in matters more than its starter price. A pipeline engine and a template-bound generator both ship “AI UGC” — they don’t actually solve the same problem.
Where the category is heading
Three trends are visible across the back half of 2026.
Compute cost is dropping fast. Cost per minute of usable UGC has dropped roughly 10× in twelve months across most vendors. The vendors that still charge premium rates are either holding back on cost pass-through (margin play) or genuinely shipping a better output (avatar realism, non-English lip-sync). Expect the cheap tier to keep flattening.
The constraint shifts upstream. Generation is no longer the bottleneck. Discoverability is — which faces and scripts perform — and that requires data the smaller vendors don’t have. The platforms with built-in competitor research and performance feedback are pulling ahead. The platforms still pitching “100 avatars and 25 languages” without a learn loop are starting to feel dated.
Platform policy is the next minefield. Meta and TikTok are both quietly tightening guidance around synthetic creators in paid placements. The tools that publish-and-monitor (rather than just generate) are going to have an easier time staying compliant because they can see when their ads get throttled. The clip-only tools are going to be harder to operate at scale.
How to pick
If you’ve read this far and you’re shopping for a tool: the cluster question matters more than the brand. Pick the cluster that matches your job, then pick the best vendor in that cluster.
- You want a polished talking-head for L&D, training, or executive comms. Avatar engine. HeyGen is the field leader, Synthesia is the enterprise alternative.
- You want unique-face variety for hook testing. Style engine. The category is fragmented; expect to switch vendors as the field consolidates.
- You want finished, published, performance-tracked ads from a single brief. Pipeline engine. This is the cluster doing the most work in 2026.
- You want cheap volume to test ideas in English only. Template-bound generator. Creatify and several smaller vendors are the volume picks.
The named winners per cluster sit in the 2026 ranking. The category map is the map; the ranking is the buy list.
Open questions for the next quarter
A few things we’re watching that aren’t answered yet in this field map:
- Whether avatar engines move into the publish-and-monitor space, or whether pipeline engines absorb avatar quality.
- Whether the platform-policy tightening forces a shift to “disclosed AI” ad formats that get their own placements.
- Whether the long tail of style engines consolidates or splinters further as compute drops.
We’ll publish a Q3 update with the same map redrawn against where the four clusters end up by September.
Letters from readers
-
Q·01 How is ad-stack funded?
We pay for every tool seat ourselves at the public plan tier, and the journal is reader-supported via the newsletter. No vendor pays for placement, and no review is sponsored.
-
Q·02 Why benchmark on the same brief instead of letting each tool play to its strengths?
Because the only fair variable in a head-to-head test is the tool. Letting each vendor pick their best demo brief is how the AI ad category got into its current marketing-led mess — every tool wins on its own showcase. Same brief means you can actually compare cost-to-published across the field.
-
Q·03 How often do you re-test tools that have shipped major updates?
Every quarter. Reviews carry a 'last tested' date in the byline. If a tool ships a meaningful capability change between quarterly cycles, we publish a field note rather than waiting — but the score on the main review only moves at the next full re-test.
-
Q·04 Can I send in a tool to be reviewed?
Yes — send a note via the contact link in the footer. We can't promise coverage of every submission, and being suggested has no bearing on the eventual verdict. Vendors who pay for seats themselves rather than offering us free credits are evaluated identically.

